This is the sixth in a series of posts on the six-session Software in Astronomy Symposium held on Wednesday and Thursday, April 3-4 at the 2018 EWASS/NAM meeting.
BLOCK 6: Software Publishing Special Interest Group Meeting
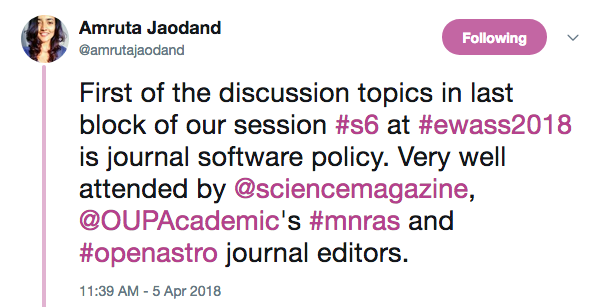
This meeting-within-a-meeting was an opportunity for journal editors, publishers, referees, abstract services, and others associated with research software publication to discuss how best to include research software in the scholarly record, improve the sustainability and reproducibility of research articles, and share information on issues and possible solutions. Representatives from Science, Nature-Springer, MNRAS, Oxford University Press, and AAS Journals were among the journals and publishers attending. As the session was open to all, researchers and software authors also attended. The agenda had three main items on it: journal software policies, ratings for numerical reproducibility, and improving instructions for authors and referees. The session was moderated by Rein Warmels (ESO, DE) and Alice Allen (ASCL, US).
 After introductions by all in the room, the first agenda item, journal policies on software, was opened for discussion. Keith Smith, associate editor for astronomy and planetary science for Science, shared that his journal is requiring that software that enables research results be shared. Editors from other journals stated that this would probably not work for them, though they are sympathetic to the importance of research software transparency. Chris Lintott, lead editor for Instrumentation, Software, Laboratory Astrophysics, and Data for AAS Journals, said that he rewrote the Journals’ software policies on his first day at the job to require formal citation of software. Smith pointed out the expectation is different for data; people are much more open about sharing observational data, and A&A (may) require it. Warmels noted a difference between data and software; the quality of observational data from an observatory is known. This is not the case with software. We cannot know the quality of the unreleased code. Amruta Jaodand asked whether publishing houses have software reviewers. The various astronomical societies’ journals do not peer-review code; there are a few journals that do perform code review of various depths, such as the Journal of Open Source Software and Software X, both of which focus on research software across disciplines.
After introductions by all in the room, the first agenda item, journal policies on software, was opened for discussion. Keith Smith, associate editor for astronomy and planetary science for Science, shared that his journal is requiring that software that enables research results be shared. Editors from other journals stated that this would probably not work for them, though they are sympathetic to the importance of research software transparency. Chris Lintott, lead editor for Instrumentation, Software, Laboratory Astrophysics, and Data for AAS Journals, said that he rewrote the Journals’ software policies on his first day at the job to require formal citation of software. Smith pointed out the expectation is different for data; people are much more open about sharing observational data, and A&A (may) require it. Warmels noted a difference between data and software; the quality of observational data from an observatory is known. This is not the case with software. We cannot know the quality of the unreleased code. Amruta Jaodand asked whether publishing houses have software reviewers. The various astronomical societies’ journals do not peer-review code; there are a few journals that do perform code review of various depths, such as the Journal of Open Source Software and Software X, both of which focus on research software across disciplines.
There was support for better software citation, but not for ratings of articles for numerical reproducibility. The idea of ratings for reproducibility led to a discussion about reproducibility itself and the issue of releasing software written for research. Adam Leary, senior publisher at Oxford University Press, said that the Journal of Biostatistics rates the reproducibility of its articles and that that journal has a reproducibility editor. The group discussed the workload this might put on reviewers along with other issues, which would slow down the review. But the real job would be for the authors! Brigitta Sipocz mentioned the need for a feedback loop, which triggered the question as to why one would want to put a lot of resources into reproducibility. Smith replied that there are cases in other sciences where whole bodies of work could not be reproduced! Warmels pointed out that a number of fake results were found by the community, not by reviewers.
Someone suggested pushing the community toward releasing software through funding councils. Lintott initially liked the idea, and stated that journals could enforce this by checking papers against funding/funders that require release. Allen found this is an intriguing suggestion. Additional discussion raised several issues with this approach. The impracticality of implementing the idea became obvious when considering the time and resources it would take and the complexity of funding, as well as varied requirements of a large number of funding organizations.
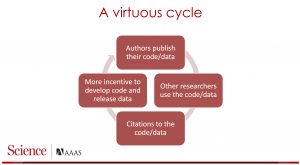
Smith’s “virtuous cycle” slide
The discussion then turned to reasons researchers do not release their software, with one advantage stated as, “If you don’t give me this funding, this research will not be done.” We have to change the way we argue for funding, then… “because as the only person who can do this, keeping my code private IS an advantage.” Jaodand mentioned that researchers get less credit for software than for research results. Smith replied that until we build up a virtuous cycle of code release, something he had mentioned in his presentation the previous day, the answer may be getting the credit system working first.
Another disincentive for code release mentioned was the possibility of someone running software incorrectly and then publishing “this code doesn’t work.” Lintott said that we should look for this and get data on it, so we can answer the question, “How often has this happened?” He also suggested looking for the positive cases, where release has been good for a developer or developer team, and provide this data to code authors.
answer the question, “How often has this happened?” He also suggested looking for the positive cases, where release has been good for a developer or developer team, and provide this data to code authors.
The next agenda item was improving instructions for authors and referees on software citation and treatment. According to Smith, Science’s instructions were improved by rewiting them to accord with the Center for Open Science‘s Transparency and Openness Promotion (TOP) Guidelines. The guidelines are very helpful, and using them provides clear instructions. Greg Schwartz, data editor for AAS Journals, asked how we could better encourage authors to read instructions. Smith waggishly replied these instructions exist so journal editors can point to them. It was suggested that journals standardize their instructions not only to help authors out but also to discourage what was referred to as “research tourism.” The TOP Guidelines were again brought up as a good tool to use for standardizing instructions. Someone asked about having a section for acknowledgements or statements for software. Smith pointed out the danger that some may think that section as a substitute for formal citation. Allen agreed that software should have formal citations, and also stated her appreciation for the Software section that AAS Journals have added to their papers. The ASCL has long been interested in seeing such a software listing in research articles (in addition to, not as a substitute for, formal citation of software). Warmels returned the discussion to the idea of standardization of instructions, asking whether this can be done. Journal representatives said the various journals do get together to standardize where they can, and are due to do so again.
The discussion migrated to openness in general. Among the suggestions for moving the discipline to be more open were to “Advertise your openness!” and to include a slide in your presentations that say your work is open and reproducible; this lets your peers know that you value openness, and can help others think about working more openly. The point was made to not rely on policing for open practices as resources aren’t available to do so. The role of education was brought up, too: Researchers need to be taught how to make their data and software open.
The final agenda item was to decide whether an on-going software publishing special interest group might be welcomed by those in the room; there was no support for this. Journals already have a method to share information amongst themselves and everyone is oversubscribed to meetings, groups, and conference calls. With that item settled, the meeting and Software in Astronomy Symposium concluded.
The ASCL thanks the Heidelberg Institute for Theoretical Studies for its generous ongoing support, which permitted two participants in this symposium to attend the EWASS/NAM meeting who would not have been able to do so without it.